数据结构和算法
绪论
数据结构概论
数据结构的定义
1.数据:描述客观事物的数和字符的集合;
2.数据项:数据最小单位;
3.数据对象:性质相同的数据元素集合;
4.数据结构:数据元素之间的关系;
- 数据逻辑结构:由数据元素之间的逻辑关系组成;
- 数据的存储结构:数据元素以及其关系的物理结构;
- 数据的运算:施加在该数据上的操作;
逻辑结构
1.定义:数据之间的抽象逻辑关系;
2.表示方法:图表表示、二元组表示;
3.逻辑结构类型:
- 集合:同属集合,无关系;
- 线性结构:一对一;
- 树形结构:一对多;
- 图:多对多;
存储结构(物理结构)
1.定义:指数据的实际存储,逻辑结构在计算机存储实现;
2.物理存输类型:
1.定义:对数据实施的操作;
运算定义和运算实现分离:基于逻辑结构定义运算,基于存储结构实现运算
2.常用数据运算类型:增删改查以及排序;
数据类型和抽象数据类型
1.数据类型:值类型,引用类型等;
2.抽象数据类型:从求解问题抽象出来的数据逻辑结构和抽象运算,与具体实现无关(重要特征是数据抽象和数据封装),算法就是抽象运算的实现;
3.抽象数据结构定义:
ADT:数据结构名(例如List);
Data:数据结构的描述(例如线性表元素一一对应);
Operation:数据结构定义了哪些操作(例如对线性表的清空、插入、添加、删除、初始化等等);算法概论
1.算法的定义:对特定问题的一种描叙,是指令的有限序列,应具有以下特征;
- 有穷性:是可以终止结束的算法;
- 确定性:相同输入相同输出;
- 可行性:算法每一步都必须是可行的,每一步都能执行有限次数完成;
- 有输入输出:输入加工对象,加功得到结果;
2.算法的设计目标:如下几点
- 正确性:对于非法的数据能够得到满足规格的结果;
- 可读可使用性:便于阅读、交流和使用;
- 健壮性:数据不合法时,也能做出相应处理;
- 时间高效率和低存储:满足时间高效率和低存储;
3.算法的描述:采用计算机语言描叙算法;
算法分析概论
1.算法分析的定义:分析算法占用的计算机CPU时间和内存空间的多少;
算法时间性能分析(重点理解)
1.时间算法类型:
- 事后统计法:统计执行时间,必须执行程序且很多因素掩盖了算法本质,如计算机速度、语言、问题规模等;
- 事前估计法:抛开问题,仅考虑算法本身的效率;
2.算法时间复杂度定义:平均情况下的问题规模n的函数的最高阶表示,推导如下
- 执行次数T(n) ==> 问题规模n的函数;
- 总算法执行时间 ==> 原操作+ T(n)(执行次数或算法频率);
- 简化算法执行时间 ==> 仅考虑执行次数T(n) ;
- 上界f(n) ==> 由T(n)对于n的阶级函数的拆解,是问题规模n的某个函数;
- 问题阶级增率比较 ==> 1(仅原操作)<${log}{2}$n<n<n${log}{2}$n<$n^2$<$n^3$<$2^n$<n!<$n^n$;
- 渐进时间复杂度(函数渐进增长问题) ==> O(f(n))(O是找出T(n)最高阶或者说最紧凑的上界);
- 平均时间复杂度 ==>最好时间复杂度(算法运气好的时间)与最坏时间复杂度(算法运气坏的时候)的折中考虑;
3.推导大O阶的方法:
- 用常数1取代运行时间中所有加法常数;
- 修改后的运行次数函数,只保留最高阶数;
- 去除最高阶的相乘系数,得到的就是大O阶;
4.算法复杂度求和求积:
- T1(n)+T2(n)=O(Max(fn,g(n))) 例如并列循环
- T1(n) * T2(n) = O(f(n)*g(n)) 例如多层嵌套循环
5.递归算法时间复杂度:自己调用自己,不能采用前面的分析方法;
算法空间性能分析
1.算法空间复杂度:记作S(n) = O(g(n)),n为问题的规模,f(n)为语句所占用的存储空间函数,解释如下;
- 局部空间:初始只分配一次空间,参与原操作完继续使用,如果算法只有该形式空间分配,即问题规模n为常数,则该算法为原地工作或就地工作算法,空间复杂度为O(1);
- 临时空间:原操作时才分配空间,原操作完即可释放,基本是其算法执行次数的考虑,空间复杂度和时间复杂度相关;
2.递归算法空间复杂度:待记;
程序概论
1.程序=数据结构+算法;
2.数据结构和算法的联系:数据存储结构会影响算法的好坏,不能只单单考虑一种,存储强、信息多的存储结构,算法会比较好设计,反而相对简单的存储结构可能要设计一套复杂的算法;
线性表
1.线性表定义:具有相同特征的数据元素的一个有限序列;
2.线性表的抽象数据类型:
ADT:线性表(List)
Data:一个有n个数据元素的数据集合,且元素类型相同,除了第一个和最后一个元素,每一个元素只有一个前驱元素和后继元素,且它之间的关系是一一对应的;
Operation:其中i是下标,e是表元素
Init():初始化操作
IsEmpty():判断是否为空
Clear():清空操作
GetElem(i):根据下标获取元素
Locate(e):根据元素获取下标,为-1则表示返回失败;
Insert(e,i):在下标位置插入元素
Delete(i):删除下标元素,并且返回其值
Lengtn():获取个数顺序存储结构
1.顺序存储结构定义:把线性表的结点按逻辑顺序依次存放在⼀组地址连续的存储单元⾥。⽤这种⽅法存储的线性表简称顺序表。是⼀种随机存取的存储结构。
- 顺序存储指内存地址是⼀块的,随机存取指访问时可以按下标随机访问,存储和存取是不⼀样的,如果是存储,则是指按顺序的,如果是存取,则是可以随机的,可以利⽤元素下标进⾏。
- 数组⽐线性表速度更快的是:原地逆序、返回中间节点、选择随机节点。
链式存储结构
1.线性链表的定义:⽤⼀组任意的存储单元来依次存放线性表的结点,这组存储单元即可以是连续的,也可以是不连续的,甚⾄是零散分布在内存中的任意位置上的。因此,链表中结点的逻辑次序和物理次序不⼀定相同。为了能正确表⽰结点间的逻辑关系,在存储每个结点值的同时,还必须存储指⽰其后继结点的地址。data域是数据域,⽤来存放结点的值。next是指针域(亦称链域),⽤来存放结点的直接后继的地址(或位置)。不需要事先估计存储空间⼤⼩。
单链表:链表的每个节点中只包含一个指针域,所以叫单链表;链表前可以有一个头节点,该节点一般不存储数据域,只存放第一个节点的指针,也可以在此存放链表长度。
静态链表:
- ⽤⼀维数组来实现线性链表,这种⽤⼀维数组表⽰的线性链表,称为静态链表。
- 静态体现在表的容量是⼀定的。(数组的⼤⼩),
- 插⼊与删除同前⾯所述的动态链表⽅法相同。静态链表中指针表⽰的是下⼀元素在数组中的位置。静态链表是⽤数组实现的,是顺序的存储结构,在物理地址上是连续的,⽽且需要预先分配⼤⼩。
- 动态链表是⽤申请内存函数(C是malloc,C++是new)动态申请内存的,所以在链表的长度上没有限制。动态链表因为是动态申请内存的,所以每个节点的物理地址不连续,要通过指针来顺序访问。静态链表在插⼊、删除时也是通过修改指针域来实现的,与动态链表没有什么分别
循环链表:
- 是⼀种头尾相接的链表。其特点是⽆须增加存储量,仅对表的链接⽅式稍作改变,即可使得表处理更加⽅便灵活。
- 在单链表中,将终端结点的指针域NULL改为指向表头结点的或开始结点,就得到了单链形式的循环链表,并简单称为单循环链表。
- 由于循环链表中没有NULL指针,故涉及遍历操作时,其终⽌条件就不再像⾮循环链表那样判断p或p—>next是否为空,⽽是判断它们是否等于某⼀指定指针,如头指针或尾指针等
双向链表:在单链表的每个结点⾥再增加⼀个指向其直接前趋的指针域prior。这样就形成的链表中有两个⽅向不同的链。双链表⼀般由头指
针唯⼀确定的,将头结点和尾结点链接起来构成循环链表,并称之为双向链表。设指针p指向某⼀结点双向链表:在单链表的每个结点⾥再增加⼀个指向其直接前趋的指针域prior。这样就形成的链表中有两个⽅向不同的链。双链表⼀般由头指
针唯⼀确定的,将头结点和尾结点链接起来构成循环链表,并称之为双向链表。设指针p指向某⼀结点双向链表:在单链表的每个结点⾥再增加⼀个指向其直接前趋的指针域prior。这样就形成的链表中有两个⽅向不同的链。双链表⼀般由头指针唯⼀确定的,将头结点和尾结点链接起来构成循环链表,并称之为双向链表。
栈和队列
栈
1.栈的定义:栈(Stack)是限制在表的⼀端进⾏插⼊和删除运算的线性表,通常称插⼊、删除的这⼀端为栈顶(Top),另⼀端为栈底(Bottom)。先进后出。top= -1时为空栈,top=0只能说明栈中只有⼀个元素,并且元素进栈时top应该⾃增。
- 顺序存储栈:顺序存储结构
- 链栈:链式存储结构。插⼊和删除操作仅限制在链头位置上进⾏。栈顶指针就是链表的头指针。通常不会出现栈满的情况。 不需要判断栈满但需要判断栈空。
- 两个栈共⽤静态存储空间,对头使⽤也存在空间溢出问题。栈1的底在v[1],栈2的底在V[m],则栈满的条件是top[1]+1=top[2]。
2.栈的应用:
- 进制转换
- 行编辑程序
- 迷宫求解
- 表达式求解
- 逆波兰式
队列
1.队列的定义:也是⼀种运算受限的线性表。它只允许在表的⼀端进⾏插⼊,⽽在另⼀端进⾏删除。允许删除的⼀端称为队头(front),允许插⼊的⼀端称为队尾(rear)。先进先出
- 顺序队列:顺序存储结构。当头尾指针相等时队列为空。在⾮空队列⾥,头指针始终指向队头前⼀个位置,⽽尾指针始终指向队尾元素的实际位置
- 循环队列:在循环队列中进⾏出队、⼊队操作时,头尾指针仍要加1,朝前移动。只不过当头尾指针指向向量上界(MaxSize-1)时,其加1操作的结果是指向向量的下界0。除⾮向量空间真的被队列元素全部占⽤,否则不会上溢。因此,除⼀些简单的应⽤外,真正实⽤的顺序队列是循环队列。故队空和队满时头尾指针均相等。因此,我们⽆法通过front=rear来判断队列“空”是“满”
- 链队列:链式存储结构。限制仅在表头删除和表尾插⼊的单链表。显然仅有单链表的头指针不便于在表尾做插⼊操作,为此再增加⼀个尾指针,指向链表的最后⼀个结点。
- 设尾指针的循环链表表示队列:则⼊队和出队算法的时间复杂度均为O(1)。⽤循环链表表⽰队列,必定有链表的头结点,⼊队操作在链表尾插⼊,直接插⼊在尾指针指向的节点后⾯,时间复杂度是常数级的;出队操作在链表表头进⾏,也就是删除表头指向的节点,时间复杂度也是常数级的。
串
递归
数组和广义表
数和二叉树
图
查找
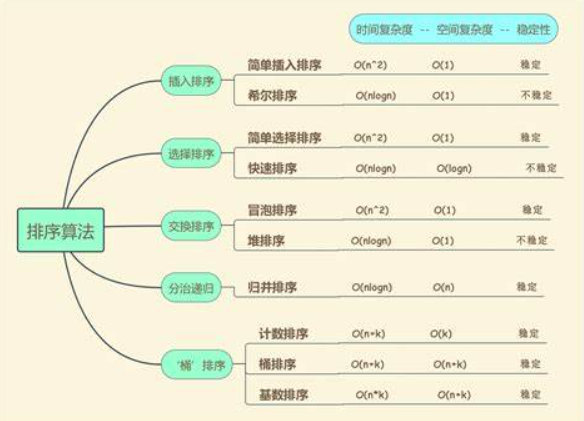
内排序
外排序
 微信
微信- 支付宝